Software-Steckbrief
| Nummer | S07-07 |
| Produkt | Urkund |
| Hersteller | PrioInfo, Box 3217, 10364 Stockholm, Sweden |
| Web-Site | www.urkund.com |
| Software-Typ | Online |
| Kosteninfo | „Urkund is a subscription based system that runs on a yearly basis. Only highschools, departments or faculties at universities and university colleges, and, through central agreement, counties, universities or university colleges are eligible to join the system.“ |
| Testdatum | 23.-24. July 2007, Retest durch die Firma am 15. September 2007 |
Testüberblick
Test 1 – 23.-24. Juli 2007
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1; | 0 | 3 | 3 | 2 | 0 | 2 | 3 | 2 | 3 | 0 | 3 | 0 | 0 | 3 | 0 | 2 | 2 | 2 | 2 |
Bewertung: 6 korrekt / 7 fast / 1 halb / 6 falsch = (3:2:1:0) 33/60 Punkte
Test 2 – 15. September 2007
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1; | 1; | 3 | 2 | 1; | 0 | 1; | 3 | 3 | 3 | 1; | 3 | 0 | 0 | 3 | 0 | 2 | 3 | 3 | 2 |
Bewertung: 8 korrekt / 3 fast / 5 halb / 4 falsch mit Gewichtung (3:2:1:0) ergibt 35 / 60 Punkte
Platz: Wir bilden den Durchschnitt der beiden Tests, (33+35)/2 macht 34, oder Platz 3, gleich mit Copyscape-Premium und PlagAware
Testablauf/Kommentare
- Die Lokalisierung ist nicht gut gelungen, es spricht immer wieder Schwedisch mit uns.
- Man lädt eine Datei hoch in dem man auf den Knopf „Search“ drückt (Screenshot 1)
- Copyright-Problem: Es gibt eine Datenbank von paper, der Benutzer kann dann das eigene aus der DB löschen lassen. Unsere sind unbeabsichtigt gespeichert worden.
- Die Nachweise der Textstellen reißen oftmals mitten im Wort ab, obwohl plagiierter Text weitergeht (Screenshot 2).
- Zeichenreihen zu 50-100 Zeichen werden geprüft
- Umlaute in Dateinamen okay
- Prozentsätze werden als Hover-Effekt der Farbfläche in der Dokumentenliste angezeigt
- Einrückungen etc. verschwinden, Zitate oder ähnlichem sind nicht ersichtlich
- Wir haben einige am 23.7. getestet, es hat 39 Minuten gedauert, bis der Upload von 20 Aufsätze fertig war (!). Ergebnisse lagen etwa 6 Stunden 25 Minuten später vor. Wir haben es am 24.7. erneut versucht, da zwei Dateien übersehen waren, es dauerte nur 44 Minuten jetzt, bis die Ergebnisse vorlagen.
- Übersichtsseite in Screenshot 3
- Sie arbeiten fieberhaft an einer neuen Fassung, haben mehrfach den Liefertermin verschoben und dann den Test für uns gemacht mit den Ergebnissen etwas halb gar gestrickt auf einer gesonderten Web-Seite präsentiert.
- Der Grundidee der neuen Oberfläche ist gut, bis auf dass die gefunden Quellen nicht nach Menge des Plagiats sortiert sind, sondern nach Reihenfolge, in der sie im Text auftauchen. (Siehe Screenshot 4) Es werden „Alternativen“ angeboten mit einer etwas verwirrenden Nummerierung: „#1:0“ ist der erste Block, wo plagiierter Text gefunden wurde, die Hauptquelle, „#1:1“ ist eine Alternative, die aber durchaus einen höheren Prozentsatz haben kann. Das ganze Ranking der Alternativen und worauf sie sich beziehen (oftmals auch Text direkt nach der Hauptquelle markiert) ist völlig unverständlich. Wenn die Alternativen ausgeklappt sind, können sie nicht wieder eingeklappt werden, bis man den nächsten Block anklickt.
- Es ist überhaupt nicht klar, wovon hier der Prozentsatz angegeben ist, ein Gesamtprozentsatz ist nicht angegeben, nur in den E-Mail-Berichten, und dort ist mehrfach von über 100% Plagiat die Rede.
- Es gibt ein „Source Summary“, die eigentlich alle Quellen übersichtsartig auflisten sollte. Oft sind „Synonyme“ (also andere URLs für dieselbe Seite) getrennt aufgelistet, und es gibt keinen Zusammenhang zwischen diesen Quellen und den im Bericht verzeichneten. Es gibt hier Quellen, die nicht im Bericht stehen, und Quellen im Bericht, die hier nicht stehen. Sogar Berichte, die 0% Plagiat gemeldet haben (Piment) haben zwei Quellen in der Summary gehabt, die zwar mit Kochen zu tun hatten, aber nicht mit Piment. Ausserdem sind einige (aber nicht alle!) der Links falsch, d.h. die HREF-Quellen fehlen öfters (aber nicht konsequent) der letzte Buchstabe, was zu teilweise nervigen, teilweise lustigen Resultaten führt. Bei der Quelle zur Buchbesprechung von Mankells „Vor dem Frost“ ist am Ende der URL ein kodiertes Datum enthalten, die alle Buchbesprechungen in diesem Zeitraum anzeigt. Als Fehlermeldung kommt dann die nette Bemerkung: „Die angegebene Rezension existiert nicht. In Mai 1973 habe ich leider keine Buchbesprechung durchgeführt.“
- Als Fazit: beim Finden von Plagiaten besser geworden, es ignoriert auch kleinere Bearbeitungsversuche – aber nicht ganze Sätze, die eingeschoben oder entfernt werden. Aber der Oberfläche ist noch extrem in der Entwicklungsphase und bedarf noch viel Arbeit, bevor es eingesetzt werden kann.
Einzeltests – Test 1
- 0: wurde mit 22% als Plagiat angegeben, 4 Stellen aus zwei Quellen sind angegeben, die aber lustigerweise selber Plagiate meiner Artikel sind (Einzelne Sätze sind in Blogs ohne Quelle wiedergegeben)
- 1: Die Musikschule wurde gefunden (Übersetzungsplagiat!), aber nur mit 7% angegeben. Es gab 58 Zeichen Übereinstimmung.
- 2: Jetzt ist mit 94 Zeichen übereinstimmung 36% Plagiat angesehen
- 4: Nur eine Quelle von 3 gefunden, dafür die größte, 34% Plagiat angegeben
- 5: In der Liste ist gelb angegeben, wenn man darauf klickt ist in der Detailansicht Orange angegeben, gefundene „Quelle“ ist eine SEO-Seite
- 6: Wieder Orange/Gelb Problem (diskrepanz Übersicht/Detail) , aber Wikipedia gefunden
- 7: Immerhin 79% Plagiat angegeben, allerdings nicht die Wikipedia, sondern eine Kopie davon
- 8: Wikipedia wird mit 21% angegeben, tatsächlich ist es eher 80%.
- 9: Zwar nur 14% Plagiat, aber die Schoolunity-Quelle angegeben
- 16: 2 von 3 Quellen gefunden
- 17: Gelb/Orange Problem, andere Quelle als die eigentliche gefunden
- 18: Nur 54% Plagiat angegeben, nur kleine Stücke des Texts sind markiert
- 19: Nur 20% Plagiat angegeben, gelb/orange Problem
Einzeltests – Test 2
- 0: Wurde mit 26% Plagiat mit 3 Quellen angegeben, die auch ein Plagiat der Seite darstellen. Aber es sind auch einmal 28 Wörter, einmal 14 orange markiert und mit sehr hohen Prozentangaben (98%!) als Plagiat verzeichnet. Ein Misverständnis ist dadurch sehr einfach.
- 1: 59% / 3 Quellen, sie haben ein Plagiat der Site gefunden, das jedoch inzwischen gelöscht worden ist. Das ist aber nicht die Quelle der Arbeit, und war nur ein kleiner Ausschnitt.
- 2: 84% / 6 Quellen, Amazon ist an erster Stelle. Es sind aber nur 2 Quellen im Bericht, auch mit ausgeklappten Alternativen, zu finden, in der Übersicht sind 2 weitere Amazon-Plagiate verzeichnet, die man aber nicht anschauen kann, weil sie im Bericht nicht vorkommen.
- 3: 118% / 4 Quellen; Abwertung, weil es 118% gar nicht geben kann – weiteres Indiz, dass es nicht so klar ist, was sie genau mit „Prozent“ meinen. Auch Abwertung, weil eine Quelle mit „http://https://“ angegeben ist. (Screenshot 5) Der Link unter dieser Angabe ist richtig gesetzt, aber das ist extrem verwirrend.
- 4: 59% / 7 Quellen, aber nur 1 von 3 Quellen gefunden, tk-logo. Wikipedia und Humboldt-Gesellschaft werden nicht gefunden.
- 5 und 6: obwohl 0% gemeldet, hat die „Source Summary“ durchaus die eigentlichen Quellen (ein Hackers Blackbook und die Wikipedia) aufgeführt, aber sie tauchen im Bericht nicht auf.
- 7: 91% / 8 Quellen, aber die Alternativen sind so verwirrend, wir blicken nicht durch, worauf sie sich beziehen, und warum sie nicht nach Prozent sortiert sind. Eine Alternative hat 90%, ist alternativ zu einer Quelle mit nur 66%, die jedoch die richtige ist. Beide Wikipedia und Sendung mit der Maus werden gefunden.
- 8: 95% / 6 Quellen, die Wikipedia-Quelle und einige Plagiate davon. Den Links der Quellen im Summary fehlt allen der letzte Buchstabe.
- 9: 18% / 2 Quellen, darunter schoolunity, es ist einfach zu sehen, dass es sich hier um eine Anfangstext bei einer Hausaufgabenbörse handelt.
- 10: 14% / 1 Quelle und nur Wikipedia, also nur 1/3 Quellen
- 11: 89% / 2 Quellen, der ersten Quelle im Summary fehlt der letzte Buchstabe (Screenshot 6)
- 12: 0%
- 13: 0% / 2 Quellen, die nicht im Report auftauchen und das Wort Piment nicht enthalten
- 14: 0%
- 15: 0%
- 16: 73% / 6 Quellen, aber nur 2/3 gefunden. Bei einigen Links fehlt der letzte Buchstabe
- 17: 20% / 5 Quellen, Buchstaben fehlen in der Übersicht
- 18: 96% / 1 Quelle, die richtige
- 19: 156% (!!) und 2 Quellen, davon ist eine nur die Literaturangabe der Anderen. Hier sieht man, dass geschützte Trennzeichen ein Problem sind, der Match-Algorithmus sieht sie als einen nicht-passenden Buchstaben an und unterbricht.
Screenshots
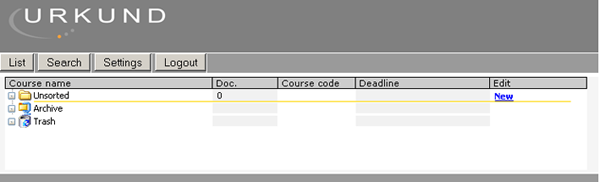
Screenshot 1: Nach dem Einloggen (altes System)
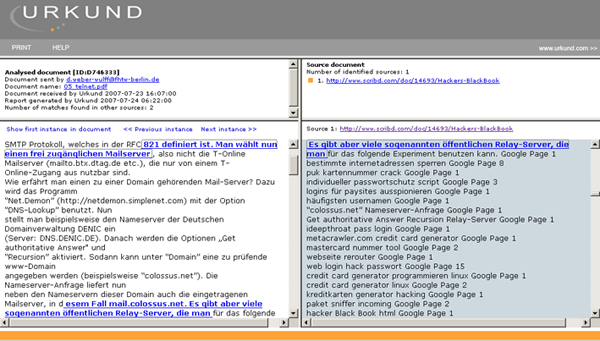
Screenshot 2: SEO-Futter im rechten Fenster? Der Text geht auch weiter…
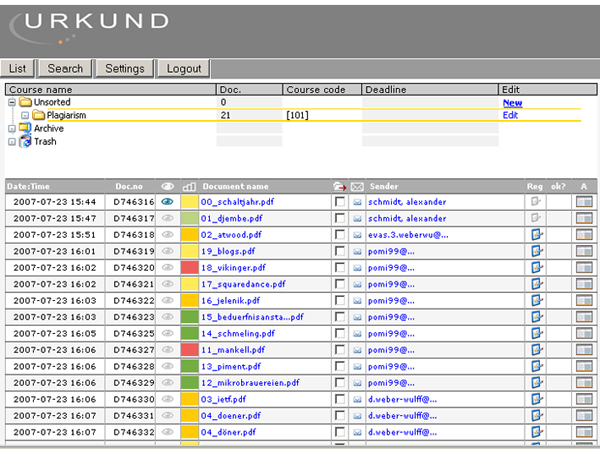
Screenshot 3: Ergebnisbericht (altes System)
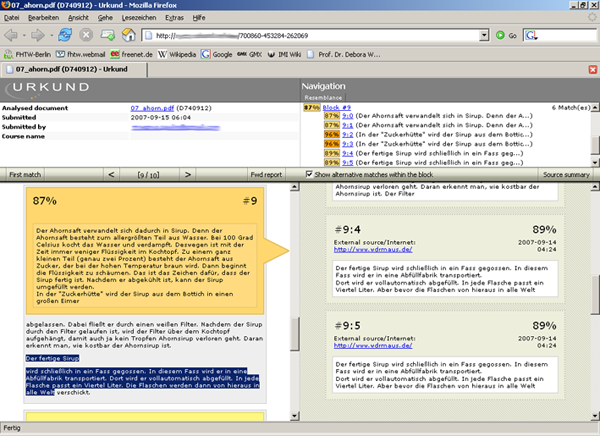
Screenshot 4: Neues Layout für die Berichte, aber aus den Prozentangaben werden wir nicht schlau
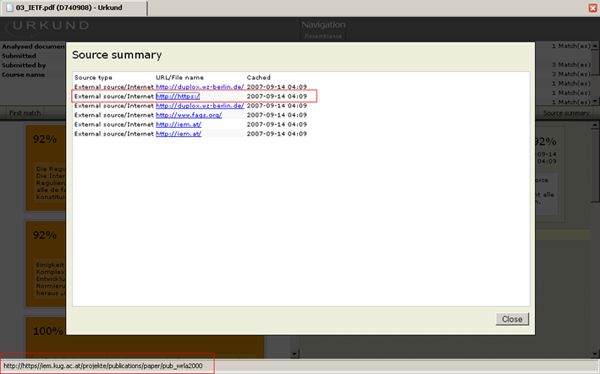
Screenshot 5: Der Link scheint merkwürdig, es ist hier etwas besseres darunter, obwohl bei etlichen den letzten Buchstaben abgehackt ist
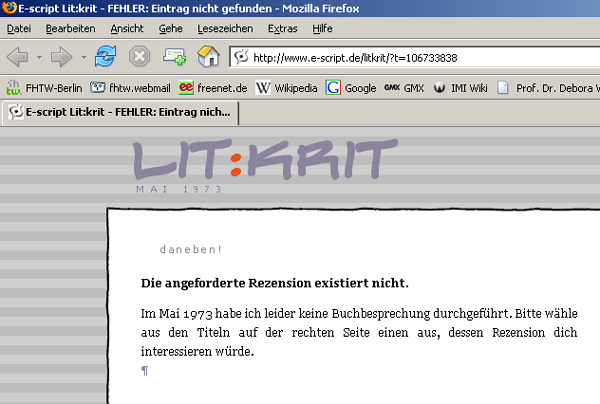
Screenshot 6: Wenn der letzte Buchstabe abgeschnitten ist, kommen lustige Fehlermeldungen (1973 waren relativ wenige Blogs online….)
Firmenwerbung
„Urkund offers a completely automated system designed to deal with the problem of plagiarism. In short it works by students sending their documents to their teachers by e-mail. In transit to the teachers the documents are checked against three main sources: The Internet, published material and documents produced by students. If any document is found to contain similarities with any source, the system will flag this as a possible instance of plagiarism. An Analysis overview is generated and sent by e-mail to the teacher. The Analysis clearly presents the information the teacher requires to make a decision“
Stellungnahme der Firma
“First of all, we would like to thank Dr. Debora Weber-Wulff and her team for her work and feedback.
We fully respect the way that the HTW has chosen to present the results but we think it is necessary to underline that:
- The distinction difference in results is small, 3 points between the top-5 results, or 5%.
- The results does not take in to account such factors as; ease-of-use (implementation, n° manipulations required by students and teachers, etc), range of sources (not only web but also commercial database partners, the internal database, etc) and the ease of integration (can it be easily integrated in an existing LMS, via available plugins or web-services).
After reviewing the comparisons between the systems and the test-teams comments we think it is relevant to first of all highlight the following:
- The ranking is in Urkund’s case based on an average, not from two test-occasions but from two fundamentally different analysis applications. The last test (Sep. 15th) relates to the new Urkund system (will be released beginning of Oct.) and can therefore not be compared to the first test-session (the results it represents are no longer relevant).
- The results from the new Urkund system shows, as expected with the re-written search algorithm, an improved result and, even more important, the lowest number of “negatives” of any of the applications tested. A “negative” result will in many cases result in the teacher not verifying the paper, consequently the paper will “slip through” whereas as indication of plagiarism (even if all sources were not identified) will result in a closer scrutiny of the paper. As an example, Urkund was the only application in the test which signalled that the “translated” document required closer scrutiny.
- Finally, the result from the second set of test were displayed in an interface which is not yet publicly released (see below).
- Why an “alternative” hit can show higher %-age similarity then the “main” hit; It is important to be able to show when a section of text has been taken from a source and then modified, in this case the system might indicate for ex a 70% similarity. If shorter parts within the highlighted text has not been modified at all (and should be within quotes) then the system will indicate a higher degree of similarity for that phrase.
- “Cannot turn off Alternative Sources”; This has been tested and it works, it should suffice to uncheck the box
- “Time to upload documents”; Firstly, the time it takes to upload files will depend on the teachers equipment (quality of internet connection, etc). Secondly, the normal method of submitting documents is via e-mail (or via an LMS platform) and not the teacher uploading them, the time to submit the document will then be the time it takes to send an e-mail.
- “Over 6 hours to get a result”; Urkund compares all submitted documents against each other, even when they are submitted at the same time, this makes it possible to detect when students have collaborated more then they are allowed to. In order to do this the system will generally deliver the results the morning after the submission. The time reported here is not related to the “performance” of the system.
- Finally, as has been pointed out, a part of this test was run on a development server hence there were some errors in the Source Summary as well some texts which have not yet been translated.”
Regarding the remarks made by the test-team, many of the ones in Test 2 are due to the situation mentioned above, the interface was located on our development environment (incorrect %-ages and other anomalies have already been corrected). However, some of the remarks require an explanation: