Software-Steckbrief
| Nummer | S07-11 |
| Produkt | TextGuard |
| Hersteller | Claus-Michael Gerigk, Wichmannstr. 4, Haus 12, 22607 Hamburg |
| Web-Site | http://www.TextGuard.de |
| Software-Typ | online |
| Kosteninfo | kostenlos, muss angemeldet sein. |
| Testdatum | 23. und 24. Juli 2007 |
Testüberblick
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 3 | 2 | 3 | 1 | 3 | 0 | 0 | 0 | 3 | 0 | 0 | 3 | 0 | 3 | 2 | 3 | 0 |
Bewertung: 8 korrekt / 2 fast / 1 halb / 9 falsch = (3:2:1:0) 29/60 Punkte
Platz: 7
Testablauf/Kommentare
- Einfach und komfortabel in der Nutzung, nur, dass man den Text mit Copy& Paste hineinkopieren muss, da der Hochlade-Knopf unter Firefox 1.0.4 nicht funktioniert.
- Der Bericht ist aber schwer lesbar, die Texte werden untereinander gebracht. (siehe Screenshot 1, Screenshot 2, Screenshot 3 )
- Es wird aber deutlich darauf hingewiesen: „Ob es sich bei dem Treffer um ein Plagiat handelt kann nur der Suchende selbst entscheiden.“
- Es gelingt mit einem anderen Browser die Dateiuploads zu machen. Die Bestätigungs-Email, dass die Dateien überprüft werden, kommen gleich vier mal.
- Findet „Trivialplagiate“ wie „t sich“ mit „hat sich“ und „findet sich“ über Wortgrenzen hinweg.
- Es werden keine Stoppwörter bei der Suche ignoriert.
- G und g werden unterschieden
- Umlaute in Namen sind okay.
- Wenn die gefundene Quelle ein PDF ist, wird ein extra Fenster aufgemacht und ein PDF-mini dort gezeigt, aber nichts ist in dem PDF markiert, das erschwert die Feststellung, wie schlimm der Plagiat ist, sehr.
- Es wird kein % gemeldet, sondern eine Anzahl an übereinstimmende Ergebnissen zusammen mit einer Farbe, die anzeigen soll, wie schlimm das Plagiat ist.
- Es kann ausgeschaltet werden, dass die Quellen in Fußnoten nicht berücksichtigt werden.
Einzeltests
- 0: 18 Ergebnisse / gelb
- 1: 0
- 2: 11 / rot, Amazon ist an zweiter Stelle
- 3: 59 / rot
- 4: 22 / rot, aber nur 2 von 3 Quellen, Wikipedia nicht erkannt
- 5: 18 / rot, sie finden eine neue Quelle für das Hacker’s Blackbook
- 6: 7 / rot, Ergebnisse nicht verstehbar, obwohl Wikipedia doch dabei ist, es wird gelb von uns vergeben weil das Resultat sehr konfus ist.
- 7: 19 / rot, beide Quellen gefunden
- 8: 12 / rot, Wikipedia an zweiter Stelle
- 9: 0
- 10: 5 / grün, Wikipedia wird gefunden, aber die eigentliche Stelle ist nicht unterstrichen. Abwertung wegen grün obwohl Plagiat.
- 11: 1 / rot
- 12: 14 / grün, als einzige Software ist die englische Wikipedia gefunden worden, aber an 7. Stelle und leider grün. Es sind viele „Plagiate“ á la „an hand“ / „can handle“ angegeben. Abwertung wegen grün.
- 13: 0
- 14: 2 / grün
- 15: 0
- 16: 15 / rot
- 17: 3 / gelb, die eigentliche Quelle ist im Detailschirm grün gefärbt, ein Plagiat davon (wortidentisch!) gelb!
- 18: 1 / rot
- 19: 12 / gelb, wenn wir die Quellen abschalten (das kann man fakultativ machen) dann 3 / grün, was zur Abwertung führt, da die eigentliche Quelle dann verschwindet.
Screenshots
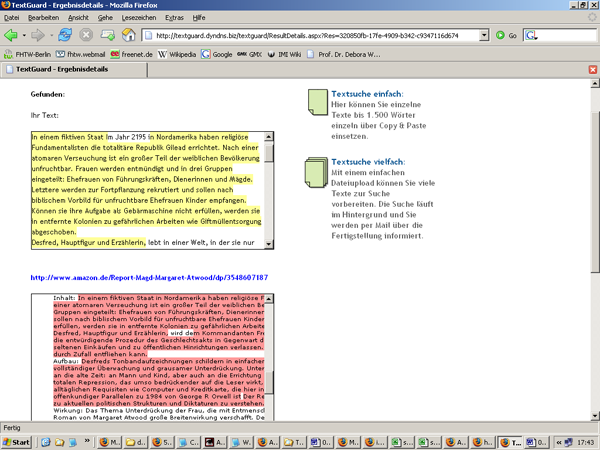
Screenshot 1: Bericht ist schwer lesbar, weil Texte untereinander sind
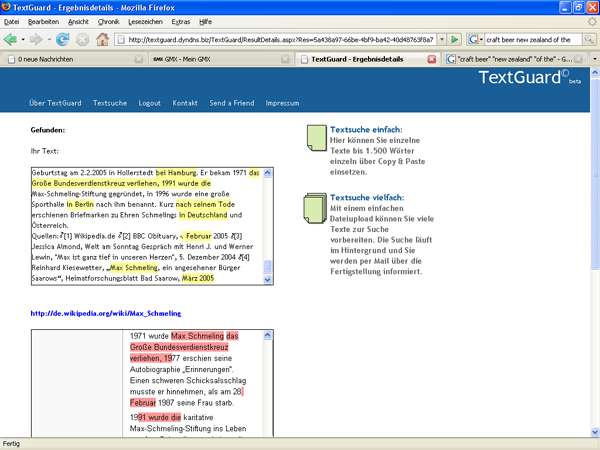
Screenshot 2: Unklar, was hier wo übereinstimmt
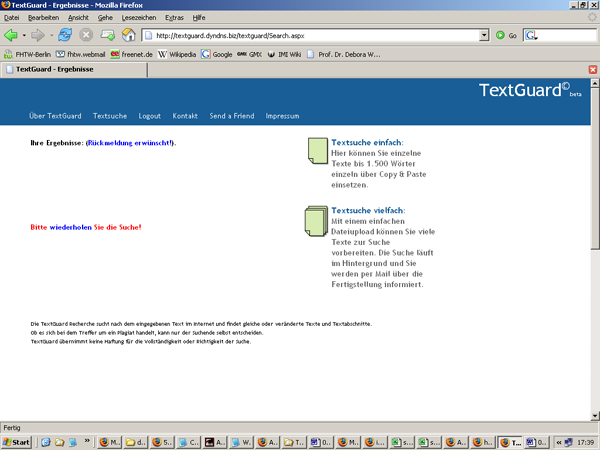
Screenshot 3: Nichts gefunden
Firmenwerbung
„TextGuard hat verschiedene Verfahren und Techniken zur Erkennung von Textduplikaten im Internet im Einsatz.
Für hohe Performance der Detektion im Internet wird eine textbasierende Vergleichsmethode eingesetzt, um in der Folge eine partielle Erkennung zu ermöglichen, z.B. wenn Quellen absichtlich verändert oder Texte modifiziert werden, sind komplexere Methoden wie Fingerprint oder Hash Verfahren notwendig.“
Firmenreaktion
Die TextGuard online Version ist noch im "Beta" Stadium. Inzwischen wandeln wir PDFs in Text um und markieren die relevanten Stellen. Der upload von mehreren Dokumenten funktioniert mit aktuellen Browserversionen. Weiter Verbesserungen werden sukzessive erfolgen. Wir beabsichtigen, als eine Form des Engagements, TextGuard für Schulen und Universitäten auch weiterhin kostenlos zur Verfügung zu stellen.