Software-Steckbrief
| Nummer | S07-06 |
| Produkt | Investigator |
| Hersteller | CFL Software Development |
| Web-Site | www.copycatchgold.com |
| Software-Typ | Collusion-Detection-System |
| Kosteninfo | |
| Testdatum | Chefprogrammierer David Woolls hat selber getestet |
Testüberblick
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Bewertung: korrekt / fast / halb / falsch = (3:2:1:0)
Platz: nicht beurteilbar
Testablauf/Kommentare
- Dieses System hat im Test 2004 erstaunlich gut abgeschnitten, obwohl es eher auf die Bestimmung von unerlaubter Zusammenarbeit (Collusion) bedacht ist und eine genaue, Englisch-sprachige Analyse durchführt. Wie damals haben wir keinen Zugang zum System bekommen, aber der Chefprogrammierer wollte unsere Aufsätze prüfen. Das System ist aber im Moment gerade überarbeitet worden und prüft nicht mehr mit dem Internet, sondern nur untereinander. Daher ist kein bewertbarer Test zu Stande gekommen.
- Update 2007-10-03: Die Firma hat beschlossen, doch noch ein Web-Interface anzubieten. Siehe Kommentare und Screenshots unten!
Einzeltests
nicht bewertet
Screenshots
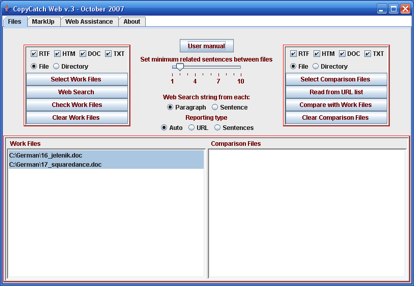
Screenshot 1: Grundbildschirm von CopyCatch (von der Firma bereitgestellt)
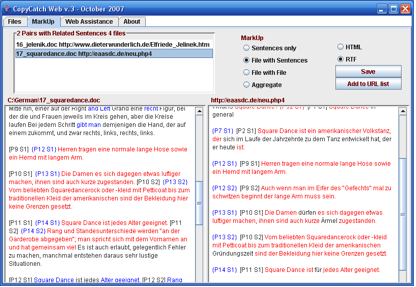
Screenshot 2: Ergebnisfenster
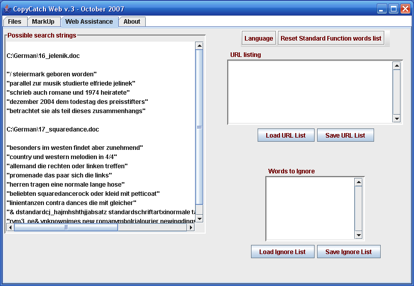
Screenshot 3: Eigene Stopwörter möglich
Firmenwerbung
„Specialists in finding similarities between documents and the detection and prevention of collusion and plagiarism“
Update 2007-10-03:
Brief 1: „Yesterday I decided to re-activate Copycatch Web, at the prompting of the US schoolteacher who first asked me to provide a simple tool for her to use. The original was built around the Google key and SOAP api. This was a beta release, meaning they weren’t going to support it, and they eventually withdrew new keys in December 2006, although the existing one works still.Yahoo have a similar facility, so I registered yesterday and modified the program to use that key. I’ve just tried it on your data and it correctly finds
jelenik and square dance,
but couldn’t find either the
mankell or blogs
which the Google based version does pick up, indicating that Yahoo’s coverage of German is not so comprehensive as Google’s.
The microbrewery (and djembe from the first test) translated articles are too hard, of course.
For completeness, it also found from the first time
ahorn,
lettau,
atwood
doner
and these three which I didn’t try earlier because I though the first 10 were all duplicates so it would be cheating to ‚find‘ them again.
- 03_IETF.doc http://duplox.wz-berlin.de/endbericht/jeanette.htm
- 06_ftf.doc http://de.wikipedia.org/wiki/Fri%C3%B0rik_%C3%9E%C3%B3r_Fri%C3%B0riksson
- 00_Schaltjahr.doc http://iq.lycos.de/qa/show/1641/Schaltjahr+-+Warum+wurde+es+wann+und+durch+wen+eingef%C3%BChrt%3F/
I’d rather given up on the program because when I tested Yahoo against Google it was nowhere near as good. Now it seems to be a bit shaky on some of the German but not too bad otherwise.
What Copycatch Web does is this:
- Reads the essay and selects the phrases most likely to have been copied, using one of my linguistic algorithms.
- Feeds these phrases, which are quite short, into the search engine.
- Compares the snippet returned with the full sentence from which the search term was taken and decides whether it is sufficiently relevant.
- Keeps a count of each relevant hit for a site
- If the number of sentences is >= the minimum set by the user, downloads each URL and performs a full Copyycatch analysis on it
- Shows the results in the same way as you are familiar with, or rather in the up-to-date style.
Copycatch Web has a couple of other useful tricks.
- It shows you the phrases it uses to search for, so you can cut and paste them into any search engine
- It can store URLs for later or future comparison
- It can read a list of URLs into its comparison side rather than a list of files and does the comparisons online.
Apart from not having access to a huge quantity of stored essays, like certain other web detectors, this provides a comprehensive web and local comparison system with no data ever leaving the institution.“
Brief 2: “ I’ve rather surprised myself by getting Copycatch Web back working again, […] I’m going to take a look at the output stage, because reading directly off the web makes it look a bit scruffy as plain text, although it is showing the dependency very clearly. But people like things to look smart.
I’ve just taken and attached some screenshots in a doc file for you. The blue words show which words are in both texts but not in position where the program thinks they are related. Investigator and Gold are a little more sophisticated in their outputs, but this is designed as a quick and dirty diagnostic tool at the moment! The teachers seem to like it as it is though.
[…] I should add that it has full local comparison facilities as well. Oh, and of course it is multilingual. I loaded up a German function word list before doing this example, using the Language button on the third screen.
I’m thinking of pricing it for individuals to buy and limiting the amount of files that can be checked at a time to around 25. I’d guess most would do less than this in fact, but in auto mode it just gets on with it while you wait. There is an interactive mode as well, which allows you to interrupt the searching if you have found a likely looking or known url. „