Software Profile | Description | Pros & Cons | Report | Usability | Summary | Screenshots | Links
Software Profile
| ID | S13-13 |
| Product | PlagiarismDetect |
| Company | No information given on website. |
| Web-Site | http://www.plagiarismdetect.com/ |
| Software-Type | Online |
| Pricing | The standard search costs 10¢ per page, the premium search 50¢. |
| Testdate | 3. May 2013 |
Description
PlagiarismDetect, not to be confused with the consimilar named Plagiarism-Detect, is unfortunately not giving information about the company behind this system. It is only stated, that the system exists since 2008.
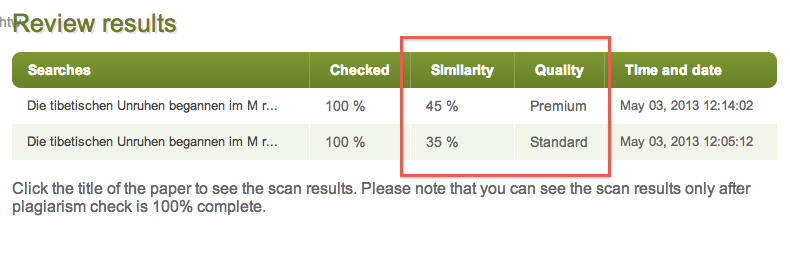
To start a plagiarism search, the user has to register and buy credits, whereby one credit suffices to check 275 words. It can be decided if the search is done in „Premium Quality“ or „Standard Quality“ . The „Standard Quality“ search indeed costs less credits but returns more poor results in many cases.
Pros & Cons
It gets clear that the system does not reveal cases of plagiarism in most instances whereby the shown percentages of the plagiarized texts are not always understandable and clear. In some cases, the system shows different percentages in the general report and in the individual view of a source. This makes it extremely confusing for people who want to check a text because they will not be sure what to believe. PlagiarismDetect states, that it can only find plagiarism correctly, if it is in English or Spanish which comes clear as it turns out that the system can indeed display hebrew characters but does not find results at all for the hebrew testcases. Like in many other Systems, Plagiarisms from Google Books cannot be found aswell.
Some concepts of the system have not been used in other systems, like the export function of a text document with all relevant sources and the offering of an API which can be used for the integration into online educational tools like Moodle. PlagiarismDetect gives the possibility to mark plagiarized passages directly on the original website of the source.
Report
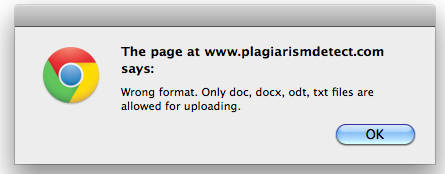
The system processes the documents in a very short time. This is good if only a few documents have to be checked, but once the user wants to upload multiple documents it takes much longer because the system does not accept ZIP files but only txt, doc and odt.
In the report, there is no side by side view and multiple sources are not marked with different colors, which makes it hard to differentiate the sources. It also complicates the report view and the usability because the user has to click on each reference to see what was found. Then, the system redirects to the source website and marks the found text.
Furthermore, it is confusing that PlagiarismDetect does not show the document title or a clear identification but the beginning of the contained text which makes it hard to search for a particular document in a set of texts.
Summary
As mentioned before, there is a difference between the standard and premium quality of plagiarism search. With standard quality one may not find all the relevant sources for the document. Thus, it is recommended to use the premium quality if possible whereas both of the different searches are returning satisfying results. The system is not convincing, neither in terms of results nor in usability of the website.
The used credit system might be useful for users who want to check a small set of documents. For users with high amounts of texts, this might lead to very high costs which is a negative aspect of the system.
The test was aborted before the last testcases because the company behind PlagiarismDetect refused to provide more credits to finish the test. This is the statement of the company:
“I have seen the plagiarism checks you made and found out that for some reason, the majority of the texts you checked are in German. As you may have seen, PlagiarismDetect works with English and Spanish texts only. Therefore, the tests you made cannot be regarded to as reliable. Unfortunately, I am no longer in the position to provide free credits for you. You can purchase more credits on the general basis – 10 cents for 1 credit. Thank you for understanding.”
It is sad to say that the test could not be continued because it was recognized in the testcases that the language was not a determinative criteria for the results of the tests. Because the credits were not provided, larger documents and homoglyphs could not be tested.
Screenshots
-
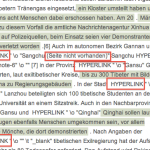
- PlagiarismDetect has problems when a text contains hyperlinks

-

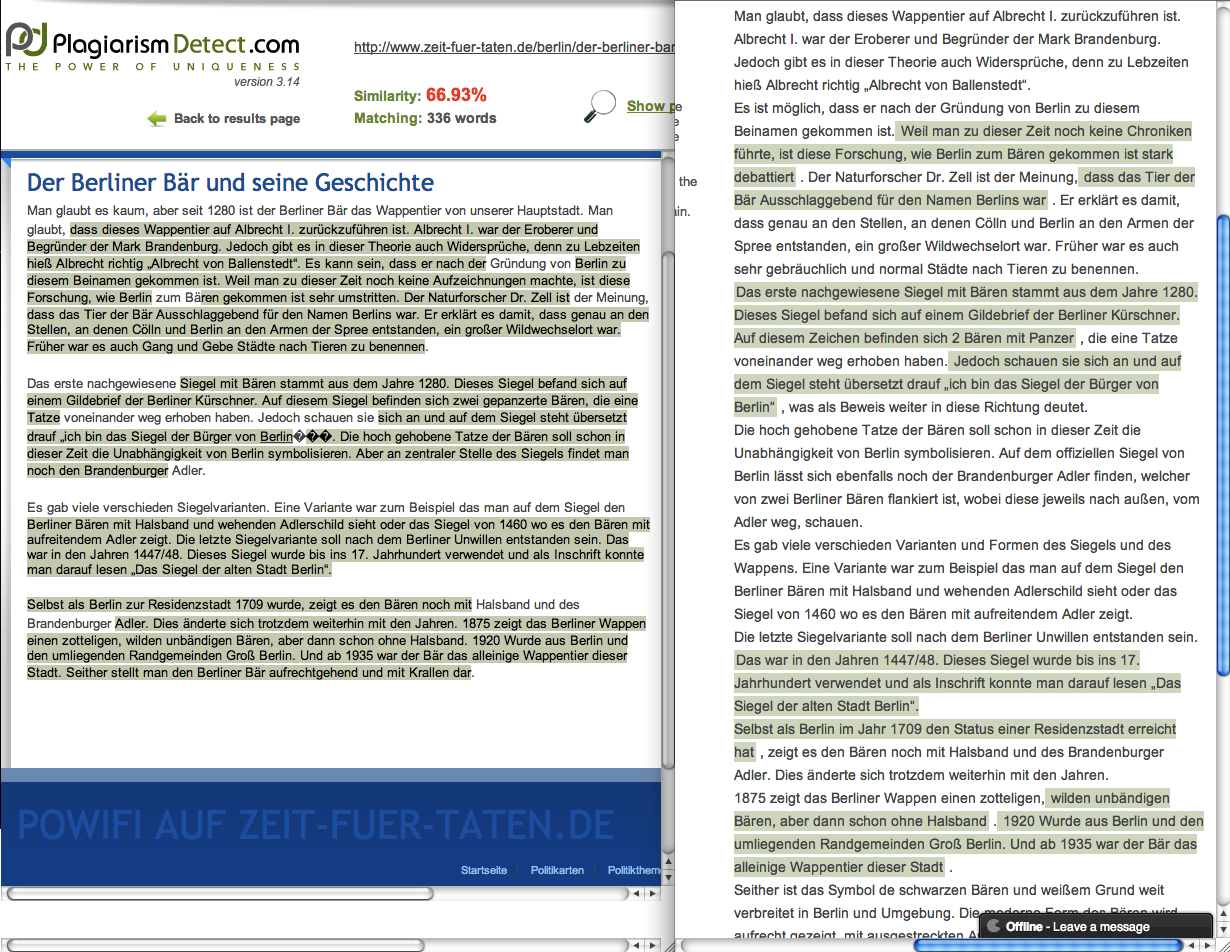
- PlagiarismDetect flags fewer sentences as plagiarism in the report view (right) than on the highlighted webpage (left)
-
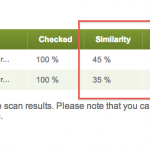
- Results in PlagiarismDetect differ depending on whether a user chooses standard or premium quality
-
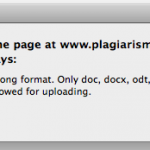
- PlagiarismDetect can not process PDF- and ZIP-files