Software-Steckbrief
| Nummer | S07-25 |
| Produkt | picapica |
| Hersteller | Bauhaus Universität Weimar, Deutschland |
| Web-Site | http://www.picapica.net/ |
| Software-Typ | Experimentell, online |
| Kosteninfo | experimentell, noch nicht erhältlich |
| Testdatum | 16.9.2007, 17.9.2007 |
Testüberblick
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0 | 2 | 3 | 2 | 3 | 0 | 1 | 2 | 0 | 0 | 3 | -1 | 0 | 3 | 0 | 0 | 0 | 1 | 3 |
Bewertung: 6 korrekt / 3 fast / 2 halb / 8 falsch / 1 irreführend = (3:2:1:0:-1) 25 /60 Punkte
Platz: 10
Testablauf/Kommentare
- Dieses experimentelle System ging durch die Presse nach Abschluss unseres Tests. Wir haben uns dennoch um Zugang bemüht, der durch den Umzug der Forschungsgruppe noch hinausgezögert wurde.
- Der Projektleiter schreibt nach fieberhaftem Rechnerumzug: „Bitte starten Sie nicht zu viele Analysen gleichzeitig, da wir so kurzfristig nur wenige Rechner organisieren konnten. Bitte haben Sie Geduld während der Analysen, auch wenn zwischenzeitlich scheinbar nichts passiert. Es handelt sich bei unserem Dienst noch um einen Prototyp, und wir arbeiten fieberhaft daran, seine Benutzbarkeit zu verbessern. „
- Man kann einen Text zur Zeit laden und zuschauen, wie die Analyse läuft. Es werden „subtasks“ generiert, die parallel laufen. Es wird dann angezeigt, wieviele davon bereits fertig sind. Zwischendurch werden noch mehr subtasks generiert, man befürchtet, es nimmt kein Ende. Es geht voran, und dann *poof* sind noch mehr subtasks. Besser nur ein Zeichen: in Arbeit, als diese Qual! Es schien bei 24 von über 1000 angehalten zu sein.
- Name des aktuell zu testenden Dokuments wird auf der Seite nicht angezeigt, der Bericht ist karg und aussagelos. (siehe Screenshot 1)
- Das Drehwurm-Icon dreht weiter, auch wenn der Test zu Ende ist.
- Es gibt keinen Link zum nächsten Dokument laden; keine Möglichkeit, einen ZIP-Upload zu organisiern.
- Immer eine Leerzeile zwischen zwei Zeilen im hochgeladenen File, damit wird recht wenig Text angezeigt.
- Man muss die ID merken, um den Bericht noch mal anzuschauen.
- Keine Statistiken werden vermerkt – wie lange, wieviele Subtasks, etc.
- Sind evtl. die Anzeigen für 1:1-Kopie und modifizierte Kopie vertauscht worden? (Screenshots 2 und 3)
Einzeltests
- 0: 26 Minuten, 1135 subtasks wurden generiert für die „Style Analysis“. Was soll das blau im ersten „Übereinstimmung“? Durch Experiment entdecken wir, dass 1:1 bzw. modifizierten Text blau bzw. gelb zugeordnet sind.
- 1: erst mal 7 Stunden gelaufen, war immer noch mit 4 subtasks offen, 111 fertig. Das Drehwurm-Icon war immer noch am Drehen, aber kein Link auf ein Ergebnisdokument. Nach einem Neustart bleibt es erneut bei 4/111 stehen. Rücksprache mit dem Entwickler – er sagt, wenn es nur noch so wenige Subtasks sind, kann man annehmen, dass er fertig ist. Und wenn keine Dokumente kommen, dann wurde nichts gefunden, es wird nur nicht explizit gesagt.
- 2: 3 gefundene Dokumente, manche Textteile werden für die gleiche Quelle sowohl als 1:1 als auch mit modifiziert markiert, was nicht sein kann, entweder oder. Es ist auch nicht klar, warum die Textepassagen nicht größer sind, sie lassen sich vorne und hinten ergänzen. Amazon wird nicht gefunden, nur Plagiate davon.
- 3: 4 gefundene Dokumente, alles andere Server-namen bei derselben Domäne, wo Kopien der Quelle lagern. Umlaute in Wörtern der Zieldokumente führen zu Problemen und unterbrechen anscheinend die Passung. Ein Plagiat dieser Sites nicht gefunden.
- 4: 3 Dokumente vorhanden bereits während das System noch rechnet, es werden 11 wenn wir beschliessen, dass es fertig ist, obwohl noch 3 Subtasks warten (250 sind abgehandelt). Nach dem Reload wird doch angezeigt, dass er fertig ist. Die Quelle tk-logo wird nicht gefunden, teilweise werden „Hits“ mit nur 6 übereinstimmenden Wörtern angezeigt. Hier hätten mindestens 2 Stilbrüche sein müssen.
- 5: 4 Quellen angegeben, davon sind 3 tatsächlich Kopien der Quelle (Hacker’s Black Book) auf verschiedenen Servern.
- 6: Hängt nach 450 Tasks. Nichts gefunden. Neuversuch, jetzt hängt er bereits bei 1 Task. Bleibt rot.
- 7: Kein Wikipedia, nur Sendung mit der Maus, es hätte mindestens 2 Stilwechsel WP – SmdM – WP sein müssen.
- 8: 19 Dokumente und 7 „mirrored Copies“, obwohl die Quelle (Wikipedia) unter den Mirrors zu finden und 9 weitere Wikipedia mirrors unter die „Quellen“ sind. Die Ergebnisse 1, 4, 5, 6, 7, 8, 9, 16 und 18 sind Blödsinn – die vier (!) Wörter „der Frankfurter Allgemeinen Zeitung“ in ein langem Artikel über die Gruppe 47, der Lettau angehörte. Alle Quellen sind Kopien, vermutlich von der Bundeszentrale für Politische Bildung
- 9: nichts gefunden
- 10: nichts gefunden
- 11: 1 Quelle, die richtige, aber wieder Überlagung von 1:1 und modified, was nicht sein kann
- 12: 1 Quelle, mit einer markierten Stelle, die kompletter Blödsinn ist, die markierte Stelle hat mit VoIP-Telefone zu tun, kein Wort passt zur Markierung im eingereichten Dokument. Hierfür wird ein Sonderpunkt ABGEZOGEN, das ist nicht nur nicht gefunden, das ist besonders problematisch, wenn eine Übereinstimmung gemeldet wird, wo keine ist. (siehe Screenshot 4)
- 13: nichts gefunden
- 14: nichts gefunden
- 15: nichts gefunden
- 16: nichts gefunden
- 17: nichts gefunden
- 18: nichts, obwohl es unter mirrored copies zwei Einträge gibt, nämlich die Quelle unter unterschiedlichen URLs. Dafür wird nur ein Punkt zuerkannt.
- 19: Quelle zweimal gefunden, einmal für den Text, einmal für die Fußnoten
Screenshots
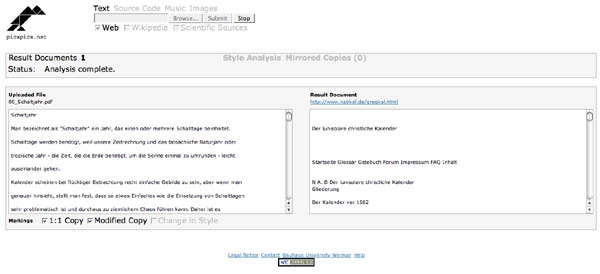
Screenshot 1: Der Bericht – nüchtern und unübersichtlich
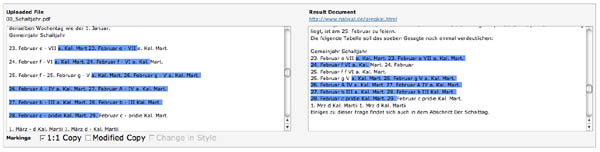
Screenshot 2: Dieses soll eine 1:1-Kopie sein, ist es aber nicht
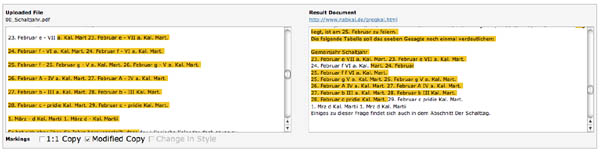
Screenshot 3: Und das soll modifizierter Text sein, man bemerke dass der Text links jeweils ein Bindestrich hat, es ist nämlich eine Tabellendarstellung gewesen

Screenshot 4 : Haben diese beide markierten Bereiche evtl. den selben Hashwert? Wir finden keine Gemeinsamkeiten.

Screenshot 5: Soll hier nicht 1:1 stehen?
Firmenwerbung:
Its underlying technologies and algorithms are developed at our research group and relate to the efficient retrieval and analysis of potentially plagiarized sources from the World Wide Web. picapica combines several approaches to plagiarism analysis: identification of copies which were taken 1:1 from a Web-document, copies that have undergone certain modifications, as well as an in-depth analyses of an author’s writing style.
Stellungnahme der Firma
„[…] manche Textteile werden für den gleichen Quelle sowohl als 1:1 als auch mit modifiziert markiert, was nicht sein kann, entweder oder.“
Tatsächlich gibt es kein „entweder oder“, da ein modifizierter Text immer auch unmodifizierte Textstellen enthält – es ist eine Frage der Granularität. Für den Anwender ist es oft sehr nützlich, eine längere Passage als modifiziert gekennzeichnet zu erhalten, als mehrere kurze Passagen als identisch. Unsere Anzeige kombiniert die Vorzüge beider Sichten, und unsere Algorithmen verhalten sich diesbezüglich also vollkommen korrekt, wenn für ein- und dieselbe Plagiatstelle sowohl modifizierte als auch unmodifizierte Plagiate angezeigt werden.
„Man kann ein Text zur Zeit laden und zuschauen, wie der Analyse läuft. Es werden „subtasks“ generiert, die in parallel laufen. Es wird dann angezeigt, wieviele davon bereits fertig sind. Zwischendurch werden noch mehr subtasks generiert, man befürchtet, es nimmt kein Ende. Es geht voran, und dann *poof* sind noch mehr subtasks. Besser nur ein Zeichen: in Arbeit, als dieser Qual! Es schien bei 24 von über 1000 angehalten zu sein.“
Tests mit Anwendern haben gezeigt, dass die Anzeige des Fortschritts von essentieller Bedeutung in der täglichen Benutzung des Dienstes ist. In einer früheren Version stand dort genau das vorgeschlagene „in Arbeit“, doch führte das dazu, dass Benutzer Analysen frühzeitig abbrachen, da sie glaubten, der Dienst sei abgestürzt. Ständige Aktualisierungen noch zu erledigender Aufgaben des Dienstes verschaffen dem Benutzer Feedback darüber, dass der Dienst noch läuft, und vermitteln einen Eindruck davon, wie lange noch zu warten ist.
„[…] Hier hätten mindestens 2 Stilbrüche sein“ und „[…] es hätte mindestens 2 Stilwechsel WP – SmdM – WP sein müssen.“
Das Erkennen von Brüchen im Schreibstil wäre auf allen Testdokumenten eine äußerst schwierige Aufgabe, da keines mehr als zwei Seiten Text umfasst hat. Für eine verlässliche Stilanalyse ist i.d.R. mehr Text vonnöten, da die eingesetzten Verfahren auf Statistiken über dem zu analysierenden Text beruhen für die eine gewisse statistische Masse notwendig ist. Referate und Abschlussarbeiten, sind im Allgemeinen deutlich länger und besser dafür geeignet. Zur Zeit gibt es kein Verfahren zur Stilanalyse oder zur computergetriebenen Forensik, das in der Lage wäre allein auf Grundlage so kurzer Textbeispiele verlässlich verschiedene Autoren voneinander zu unterscheiden. Siehe dazu die Arbeiten von u.a. Hirst. Deshalb ist es für uns eine Überlegung, die Stilanalyse für kurze Dokumente einfach abzuschalten.