Software-Steckbrief
| Nummer | S07-20 |
| Produkt | S07-22 |
| Produkt | PlagAware |
| Hersteller | Dirk Malthan, Ruländerweg 14, 89075 Ulm Tel.: +49 731 9214253 E-Mail: info@plagaware.de |
| Web-Site | http://www.plagaware.de/ |
| Software-Typ | Online, prüft laufend aber nur HTML-Seiten bzw. Domänen, die ein auf die Firma verlinktes Logo beinhalten. |
| Kosteninfo | aus http://www.plagaware.de/informationen/preise/ :free: 1 scan / Tag (max. 500 pages, 5 domains)4.49 EUR (light): 5 scans / Tag (max. 1500 pages, 5 domains); 0.03 EUR pro zusätzlichen scan
8.99 EUR (standard): 20 scans / Tag (max 5000 pages, 20 domains); 0.02 EUR pro zusätzlichen scan 14.99 EUR (premium): 50 scans / Tag (max 25000 pages, 50 domains); 0.01 EUR pro zusätzlichen scan |
| Testdatum | 11. September 2007 |
Testüberblick
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0 | 3 | 3 | 2 | 0 | 1 | 3 | 3 | 1 | 1 | 3 | 0 | 0 | 3 | 0 | 2 | 3 | 3 | 0 |
Bewertung: 9 korrekt / 2 fast / 3 halb / 6 falsch = (3:2:1:0) 34/60 Punkte
Platz: 3, gleich mit Urkund und Copyscape Premium
Beste Handhabung, Beste Berichtsqualität (subjektiv)
Testablauf/Kommentare
- Wir haben zunächst getestet ohne das Logo, und in der Tat, es verweigert seine Dienste ohne die absolut korrekte Anbringung von Logo und Link. Das wird natürlich auf Dauer den Google-PageRank von PlagAware sehr hoch treiben, wenn viele Seiten darauf verlinken. Zur Zeit des Tests hatte PlagAware ein Google PageRank von 0 (plagiat.htw-berlin.de am gleichen Tag 5).
- Die Handhabung vom System ist sehr angenehm und vor allem intuitiv. (Screenshot 1) Man trägt die URLs ein, und die Prüfungen beginnen sofort. Man kann auch während eines „Scans“ bereits die ersten Ergebnisse anschauen. Es wird auch nicht gleich ein Plagiatsvorwurf erhoben, sondern einfach Statistiken zurückgeliefert, Schlüsse muss man selber ziehen. Man bekommt MW= Matching Words, MP= Matching Phrases und SP= Suspicious sites gemeldet. Die Angaben für unseren Test sind unten angegeben.
- Jeder Scan liefert teilweise unterschiedliche Werte zurück, das ist sicherlich darauf zurückzuführen, dass unterschiedliche Datenbanken angefragt werden.
- PlagAware erkennt keine Quellen, die nicht in HTML-Format vorliegen, das führte in der Gesamtbewertung zur Abwertung, da es einige PDF Quellen im Test gibt.
- Das System hat Probleme mit Framesets und wertet nur den obersten Frame aus.
- Der Scan findet automatisch statt, je nach Auslastung; in unserem Test dauerte es zwischen 3:25 und 14:14 Minuten für die Ergebnisse, ein akzeptabler Wert.
- Es gibt die Möglichkeit, Sites auf einer „Whitelist“ einzutragen (Screenshot 4), damit sie nicht zukünftig als Plagiate angesehen wird. Das ist sehr angenehm wenn man unter verschiedenen URLs gleiche Inhalte anbietet.
- Umlaute bereiten dem System keine Probleme.
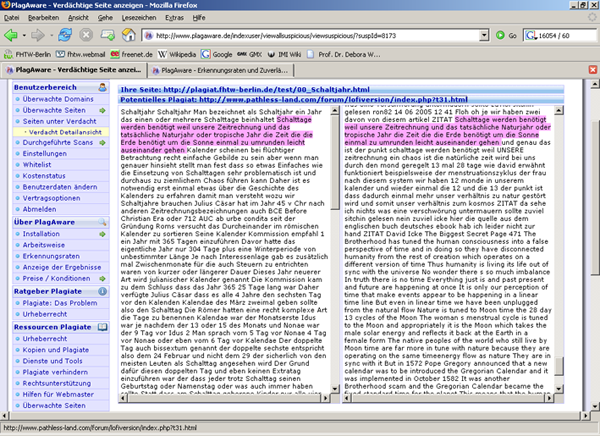
- Die Berichte sind sehr übersichtlich dargestellt und intuitiv bedienbar. (Screenshot 2) Dargestellt werden jeweils Original und eine der Verdachtsquellen, mit den Übereinstimmungen entsprechend eingefärbt. Ein Klick auf einen markierten bereich synchronisiert beide Fenster, so dass die Textstellen sich gegenüber stehen.
- Störend an den Berichten war nur, dass CSS bzw. JavaScript-Code mit dargestellt wird, was für nicht-Informatiker recht verwirrend sein kann. Das sollte aus Original und Verdachtsquelle erst mal entfernt werden.
- Es gibt eine tägliche E-Mail mit den aktuellsten Ergebnissen, die sehr übersichtlich aufbereitet ist und mit entsprechenden Links angeboten wird. Die erlaubt ein geschmeidiges Arbeiten mit der Seite und den Informationen.
- Die Site bietet viele seriöse Informationen zum Plagiat und Urheberrecht an.
- Wenn das System auch noch PDFs auswerten könnte, wäre es noch besser.
Einzeltests
- 0: 43 MW/2 MP/1 SP
- 1: 28 / 4 / 1 – Plagiat unserer Übersetzung gefunden (jedoch nur 2 Zeilen übernommen)
- 2: 381 / 4 / 10
- 3: 125 / 7 / 4, ein Plagiat ist an erster Stelle, die eigentliche Quelle an den Stellen 3 und 4.
- 4: 157 / 15 / 29, 2 von 3 Quellen gefunden, tk-logo fehlt.
- 5: 49 / 4 / 4, die ersten beiden „Quellen“ sind kompletter Blödsinn. Quelle war pdf, also scheint das System keine PDFs lesen zu können.
- 6: 490 / 19 / 4, immerhin ist die Wikipedia an Stelle 2
- 7: 405 / 10 / 22, an erster Stelle die Sendung mit der Maus, danach viele Wikipedia-Plagiate vor der Wikipedia
- 8: 912 / 87 / 9, es werden WP Plagiate, aber auch Wikipedia gefunden
- 9: 50 / 8 / 1, nach diesem Ergebnis ist es nicht als Plagiat erkennbar, weil nur vereinzelt Halbsätze markiert sind. Wenn man den Text genauer liest sieht man aber, dass der Aufsatz, den wir bei schoolunity gekauft haben, höchstwahrscheinlich von dieser Quelle abstammt, denn die Struktur ist identisch, die gefundene Quelle ist besser beschrieben.
- 10: 109 / 7 / 5, Wikipedia wird gefunden, sonst nur Kleinigkeiten – der PDF-Quelle ist nicht gefunden worden
- 11: 568 / 13 / 1, es wird nur eine Quelle geliefert, die richtige!
- 12: 0 / 0 / 0
- 13: 0 / 0 / 0
- 14: 0 / 0 / 0
- 15: 0 / 0 / 0
- 16: 196 / 7 / 2, 2 von 3 Quellen gefunden, die Übersetzung nicht
- 17: 92 / 4 / 4, immerhin ist die Quelle dabei
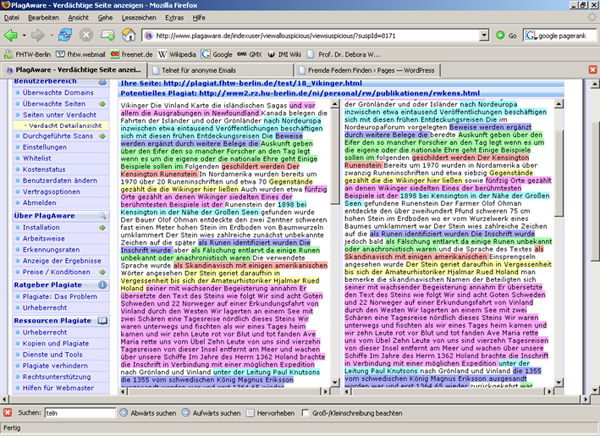
- 18: 694 / 29 / 1, genau die Quelle, kommt auch mit den Bearbeitungen zu Recht (Screenshot 3)
- 19: 0 / 0 / 0, die Quelle ist auch PDF
Screenshots

Screenshot 1: Der Benutzerbereich ist sehr aufgeräumt
Screenshot 2: Einfache Ergebnisse
Screenshot 3: Auch Bearbeitungen werden relativ übersichtlich dargestellt

Screenshot 4: Man kann verdächtige Seiten einfach ausschliessen, in dem man sie auf Whitelists setzt
Firmenwerbung
„Der Content Ihrer Webseite ist das Kapital Ihres Webauftritts – und ein lohnendes Ziel von Trittbrettfahrern, die mit Plagiaten und Kopien das Ranking Ihrer Seite in Suchmaschinen gefährden, Besucher von Ihrer Seite abziehen und damit erhebliche Verluste bewirken.“
„PlagAware fahndet nach Webseiten, die Teile Ihres Contents wortgleich vewenden. Dazu werden Wortgruppen Ihrer Webseite („Phrasen“) gezielt gesucht und die Ergebnisse detailliert ausgewertet. Webseiten, die als verdächtig eingestuft werden, werden Ihnen farbig markiert im Benutzerbereich angezeigt.“
Stellungnahme der Firma
Im Übrigen wird ab Anfang November eine neue Version der Scan-Engine online gehen, die (neben Detailverbesserungen) auch Framesets, PDF, DOC, PPT und OpenOffice-Dokumente verarbeiten kann, sodass wir schon sehr gespannt sind, wie die Ergebnisse bei dem nächsten Test ausfallen.