Software-Steckbrief
| Nummer | S07-12 |
| Produkt | DOC Cop Plagiarism Detection |
| Hersteller | Doc Cop, PO Box 477, Essendon, Vic, 3040, Australia |
| Web-Site | http://www.doccop.com/ |
| Software-Typ | online |
| Kosteninfo | |
| Testdatum | 23.-24. Juli 2007 |
Testüberblick
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0 | 1 | 1 | 0 | 0 | 2 | 1 | 2 | 0 | 0 | 3 | 0 | 0 | 3 | 0 | 0 | 1 | 0 | 0 |
Bewertung: 3 korrekt / 2 fast / 4 halb / 11 falsch = (3:2:1:0) 17/60 Punkte
Platz: 11
Testablauf/Kommentare
- Man muss mit Copy & Paste das Dokument in ein HTML-Form-Field hineinkopieren. Es darf (kostenlos) maximal 750 Wörter getestet werden. Nach einiger Zeit dürften wir dann nur 500 Wörter testen. (Screenshot 1). Inzwischen gibt es keinen kostenlosen check mehr. Man muss „Tokens“ erwerben.
- Ergebnisse werden per E-Mail zugesandt. Man darf erst das nächste Dokument testen, wenn der Bericht vom vorherigen versandt wurde. (Screenshot 3)
- Wenn man aus versehen etwas klickt und zurück gehen muss, ist alles wieder leer.
- Speichert automatisch („future check“) die Dokumente in einer Datenbank, der Default ist aus.
- Wir haben versucht mit spamgourmet-Adressen alle loszuschicken, die wurden aber irgendwie als spamadressen angesehen und deregistriert.
- Wir haben (2 Tester) auch viele E-Mail accounts, alle wurden eingesetzt, um die Tests zu machen. Nicht alle haben Ergebnisse geliefert. Manche Ergebnisse waren schon in 13 Minuten da, andere haben 12 Stunden gebraucht. Im Durchschnitt für die Arbeiten, die geprüft wurden, waren es 4:53:30 pro Aufsatz, was indiskutabel ist.
- Es war früh morgens schneller als abends.
- Umlaute funktionieren nicht.
- Es sucht nach Zeichenreihen (á 12 Wörter) in Google, Yahoo! und MS Live. Nach jeder Suche wird die Zeichenreihe um ein Wort weitergeschoben, und erneut gesucht.
- Um die Quellen zu finden muss man dann selber auf den entsprechenden Knopf für eine der Suchmaschinen klicken.
- Die Berichte sind sehr lang, sehr unübersichtlich, und sehr schwer handhabbar – es wird erwartet, dass man selber noch mal bei Yahoo, Google und MSN sucht – also kann man das doch gleich machen? (Screenshot 2)
- Die %-Zahlen sind auch noch falsch gerechnet – es ist uns komisch vorgekommen, wir haben nachgerechnet. Sie berechnen den %-Satz der Suchanfragen (was Schwachsinn ist) und nicht auf der Basis der Grundgesamtheit. Wir haben ein Dokument nachgerechnet, bei dem 19% als Plagiat errechnet wird (und das tatsächlich ein Vollplagiat ist), also 72/371 Suchanfragen. Tatsächlich grün eingefärbt war 990/2651 Zeichen, was 37% des dargestellten Texts ist!
- Ein Aufsatz wurde zwei mal verschickt, es kamen unterschiedliche Resultate: 68/724 und 13/456 – bei identischer Anfrage.
- Wir haben auch die Collusion Detection versucht zu testen, es ist kein Ergebnis zurückgekommen.
- Wenn man die Links verfolgt, die grün angegeben sind, bekommt man z.B. Wikipedia-Clones, aber die WP selber nicht. Bei einigen Testfällen fand Google nichts, weil der Suchbegriff in „…“ eingeschlossen worden ist, aber vorher die Sonderzeichen entfernt worden sind.
Einzeltests
- 2: Meldet 19% – 72/371, bei einem Totalplagiat ist das ein bisschen wenig.
- 3: Meldet 9% – 68/724, dito
- 4: Meldet 4% – 25/563
- 5: Meldet 3% – 13/456
- 6: Meldet 16% – 83/525, aber Wikipedia gefunden
- 7: Meldet 9% – 45/520, findet nicht die Wikipedia, aber vereinzelt Kopien (nicht bei Google, weil Sonderzeichen entfernt!)
- 8: Meldet 26% – 138/532
- 9: Meldet 0% – nach 11 Stunden!
- 10: Meldet 0% – 0/513
- 11: Meldet 21% – 125/606
- 12: Meldet 0% – 0/654
- 13: Meldet 0% – 0/439
- 14: Meldet 0% – 2/533, zeigt aber nur eine Übereinstimmung an: „SCHMELING WURDE AM 28 SEPTEMBER 1905 IN KLEIN LUCKOW IN DER UCKERMARK GEBOREN“ (Großbuchstaben im Bericht, um die Stelle hervorzuheben).
- 15: Meldet 0% – 0/538
- 16: Meldet 4% -16/412
- 17: Meldet 7% – 34/477, ist immerhin eine korrekte Quelle dabei, also gelb trotz sehr niedrigem Prozentsatz
- 18: Meldet 11% – 78/733, dieser Aufsatz hat ein Zitat (zwar auch geklaut, aber korrekt angegeben). Durch das entfernen aller Absätze und Sonderzeichen ist es im Bericht nicht ersichtlich, dass ein Großteil der gefundene Übersetzung die Wiedergabe des Runensteins ist, daher wird dieser nicht als korrekt gewertet.
- 19: Meldet 0% – 0/730
Screenshots

Screenshot 1: Eingabefeld
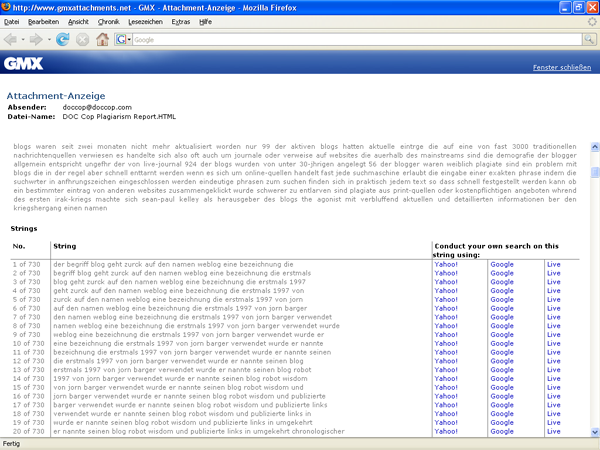
Screenshot 2: Ein völlig unübersichtlicher Bericht – und die Quellen soll man sich noch mal selber erarbeiten
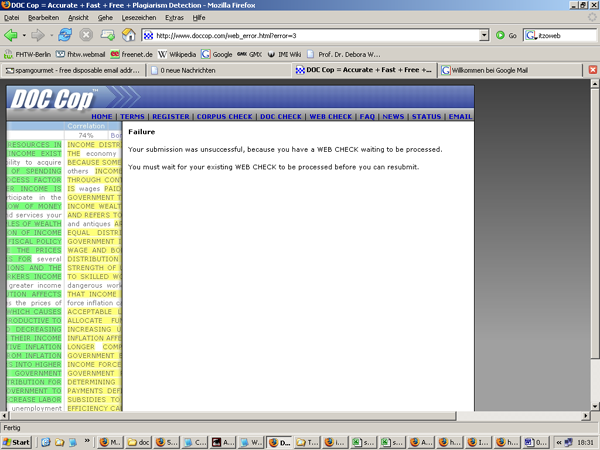
Screenshot 3: Nur ein Dokument gleichzeitig, bitte!
Firmenwerbung:
DOC Cop is lightning fast:
* When processing documents, DOC Cop scans a document of up to 500 words against the web in minutes.
* When processing a corpus, DOC Cop scans one million words, a thousand thousand-word documents or Homer’s Odyssey against Joyce’s Ulysses within 20 minutes.
Features:
* 4-hour turnaround
* Create and submit your own corpus
* Detailed reports
* Entirely web based, no installation necessary
* Exclude repetitious text (e.g. the question itself)
* Include your own material (e.g. lecture notes)
* Online support
* SSL Security (128 Bit)
* DOC Cop Plagiarism Detection guarantees that no submission is copied, retained elsewhere, passed on to others or sold. DOC Cop Plagiarism Detection guarantees to delete every submission once processing is complete.
DOC Cop has a growing number of users in Australia, Canada, the US, the UK, South Africa and Hong Kong.